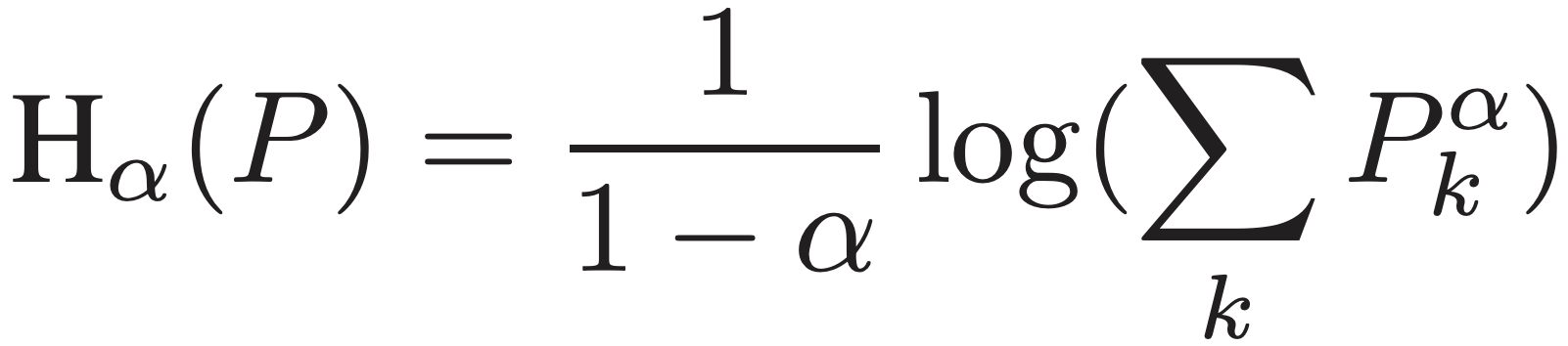|
Ligong Han | 韩立功
I am a Principal Research Scientist at Red Hat AI Innovation and MIT-IBM Watson AI Lab, working on Generative AI with a focus on efficient and controllable generation, particularly in diffusion models, LLMs and diffusion LLMs. I obtained my PhD in Computer Science from Rutgers University in 2024, advised by Prof. Dimitris Metaxas. During my PhD, I've spent time at Google Research, MIT-IBM Watson AI Lab, Snap Research, NEC Labs America, Tencent, and the Robotics Institute working as a research intern.
Previously, I earned my master's degree from Carnegie Mellon University and my bachelor's from Chien-Shiung Wu College, Southeast University.
Email: lastnamefirstname [at] gmail [dot] com or firstname.lastname [at] rutgers [dot] edu
Email /
CV /
Google Scholar /
Github /
LinkedIn /
Twitter
|

|
|
Research
Selected publications are highlighted. (* equal contribution, † corresponding author)
|
|
|
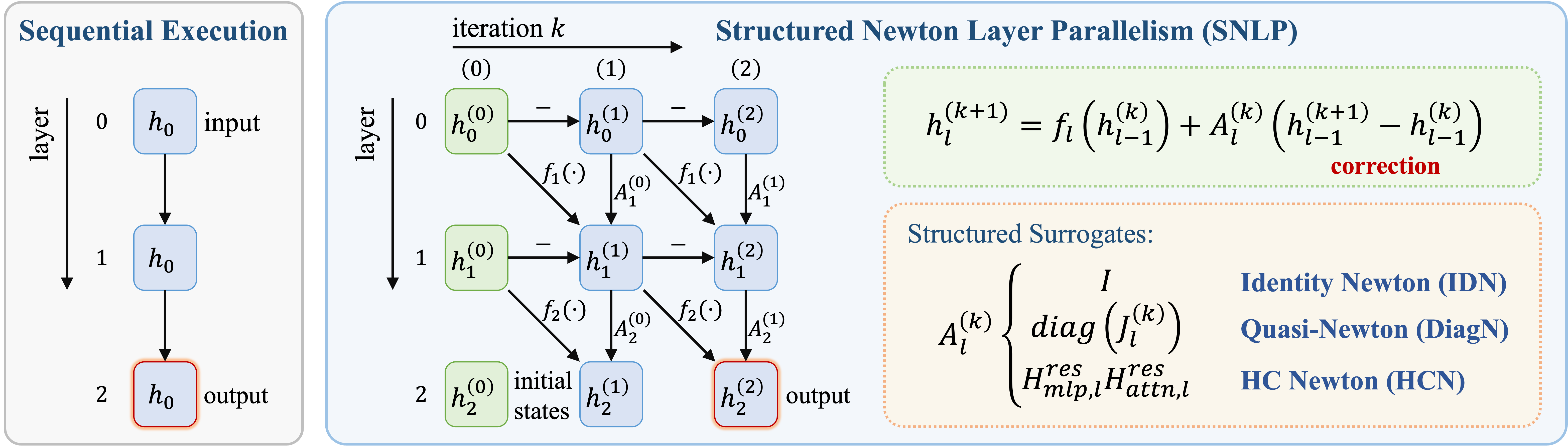
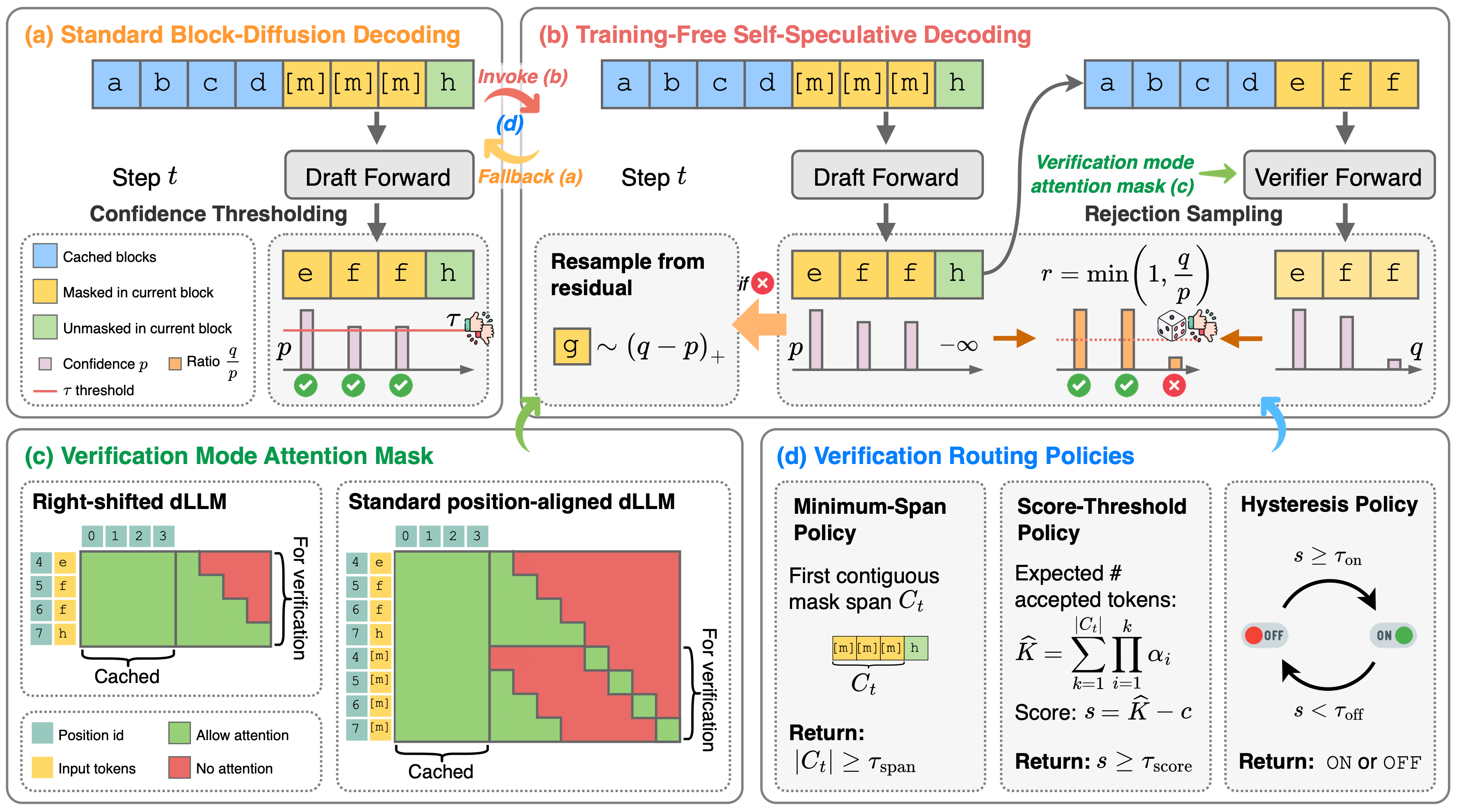
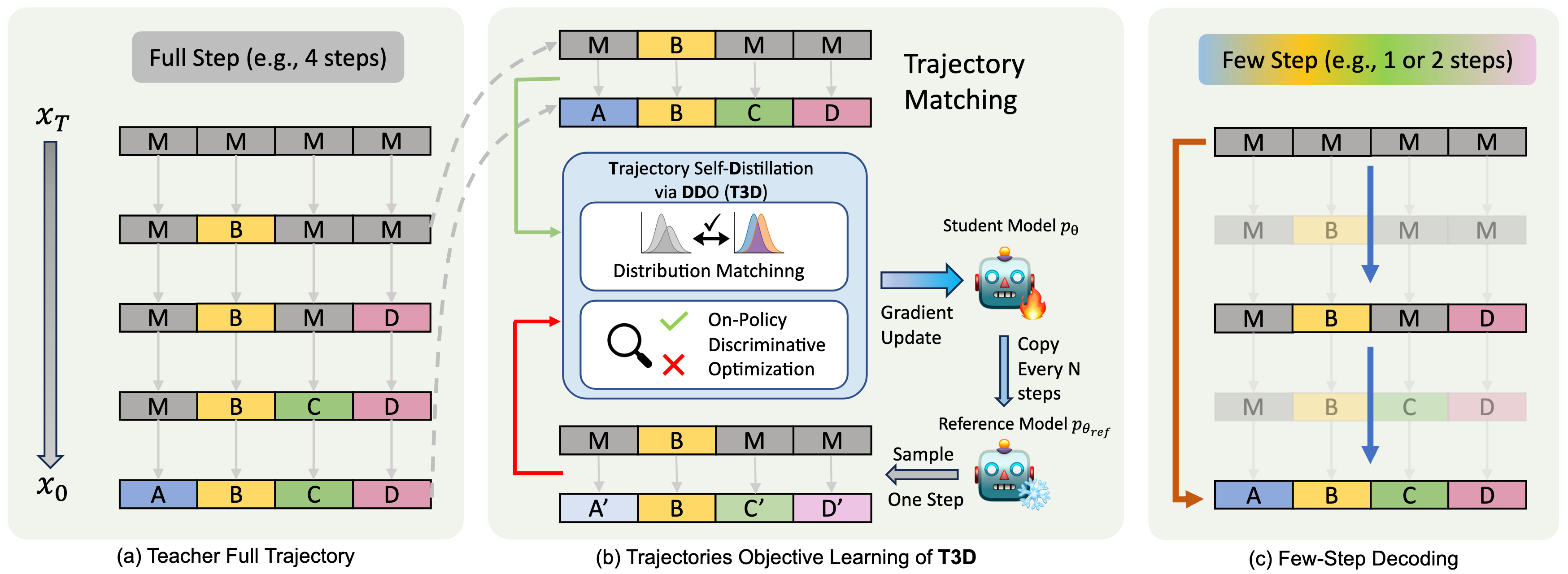
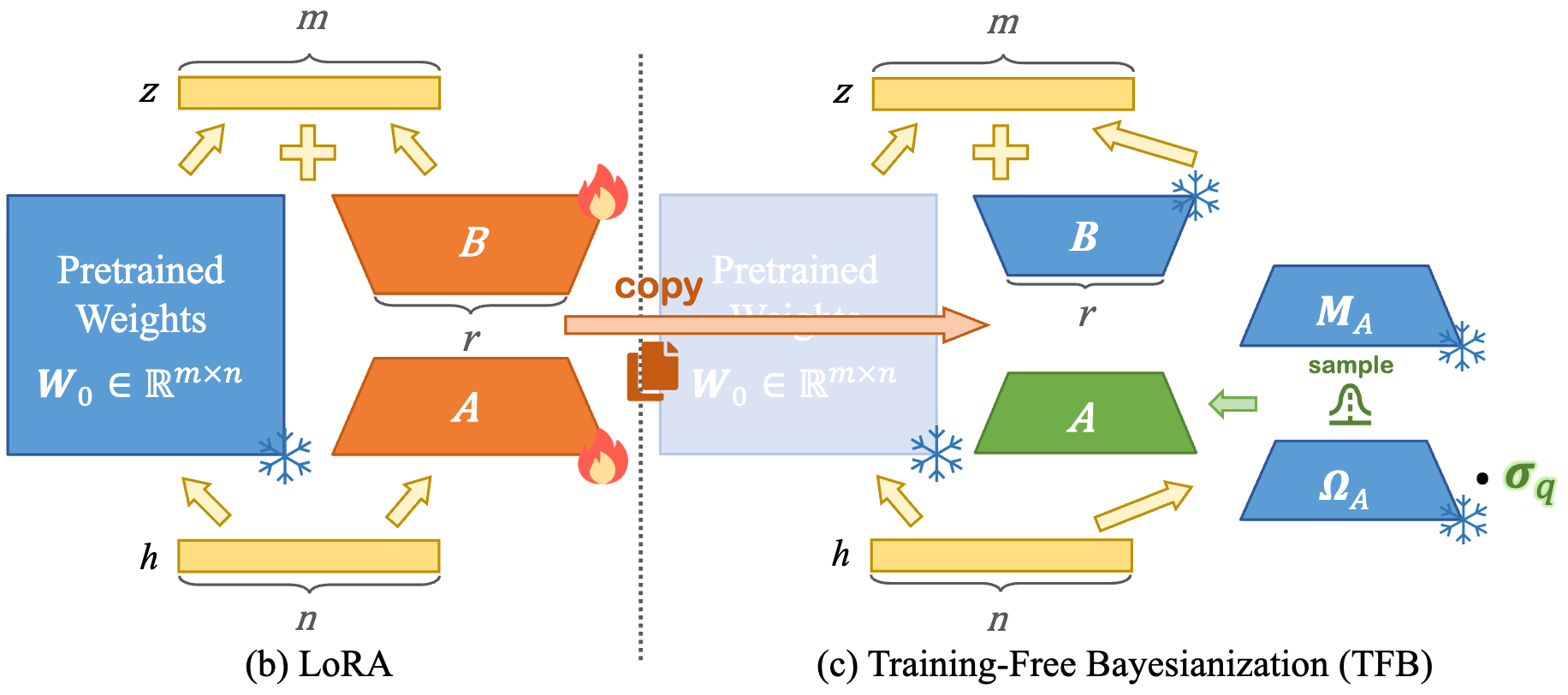
T3D: Few-Step Diffusion Language Models via Trajectory Self-Distillation with Direct Discriminative Optimization
Tunyu Zhang*, Xinxi Zhang*, Ligong Han, Haizhou Shi, Xiaoxiao He, Zhuowei Li, Hao Wang, Kai Xu, Akash Srivastava, Hao Wang, Vladimir Pavlovic, Dimitris Metaxas.
arXiv, 2026
[arXiv]
[Github]
[Slides]
[bibtex]
|
|
|
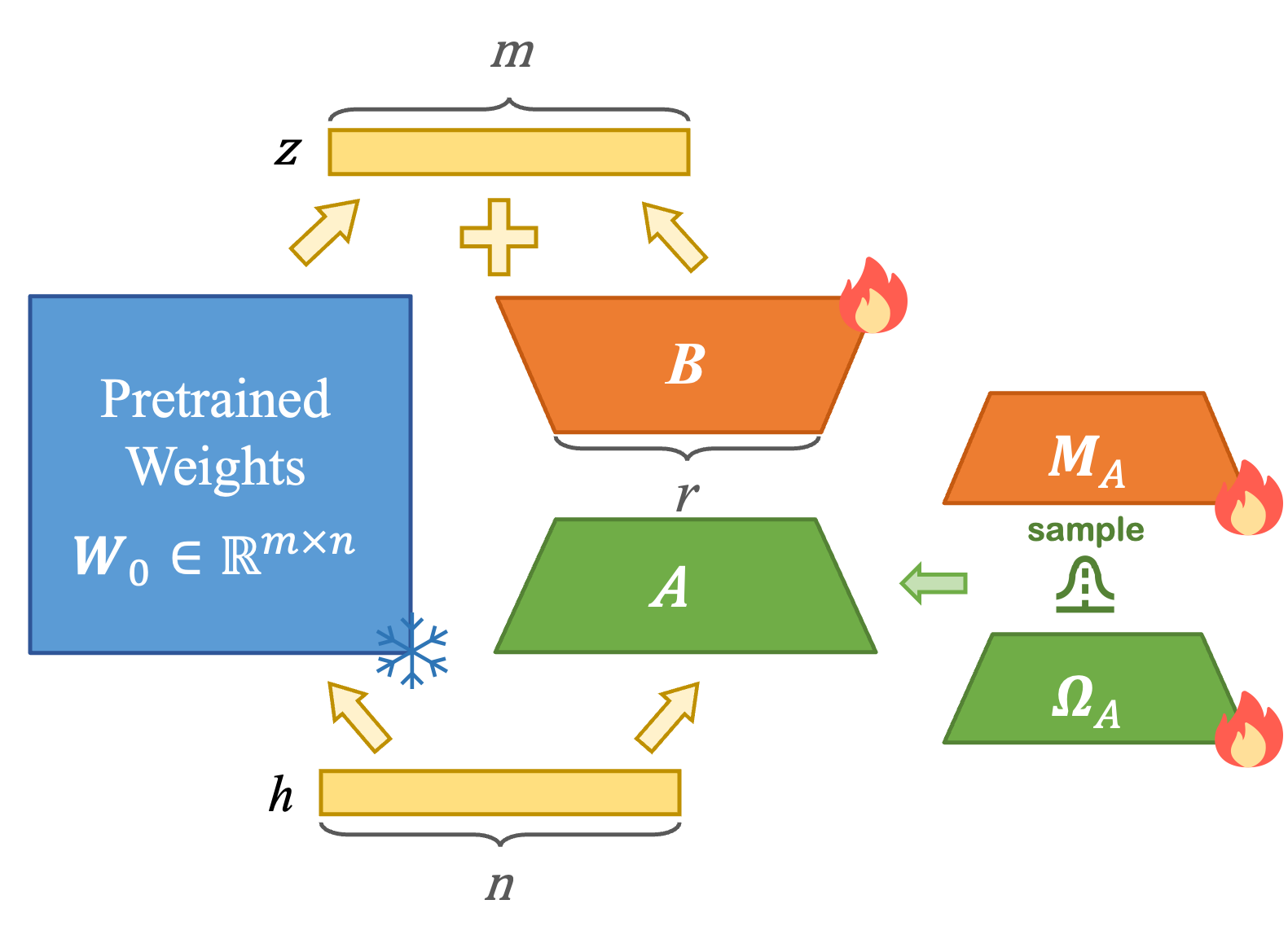
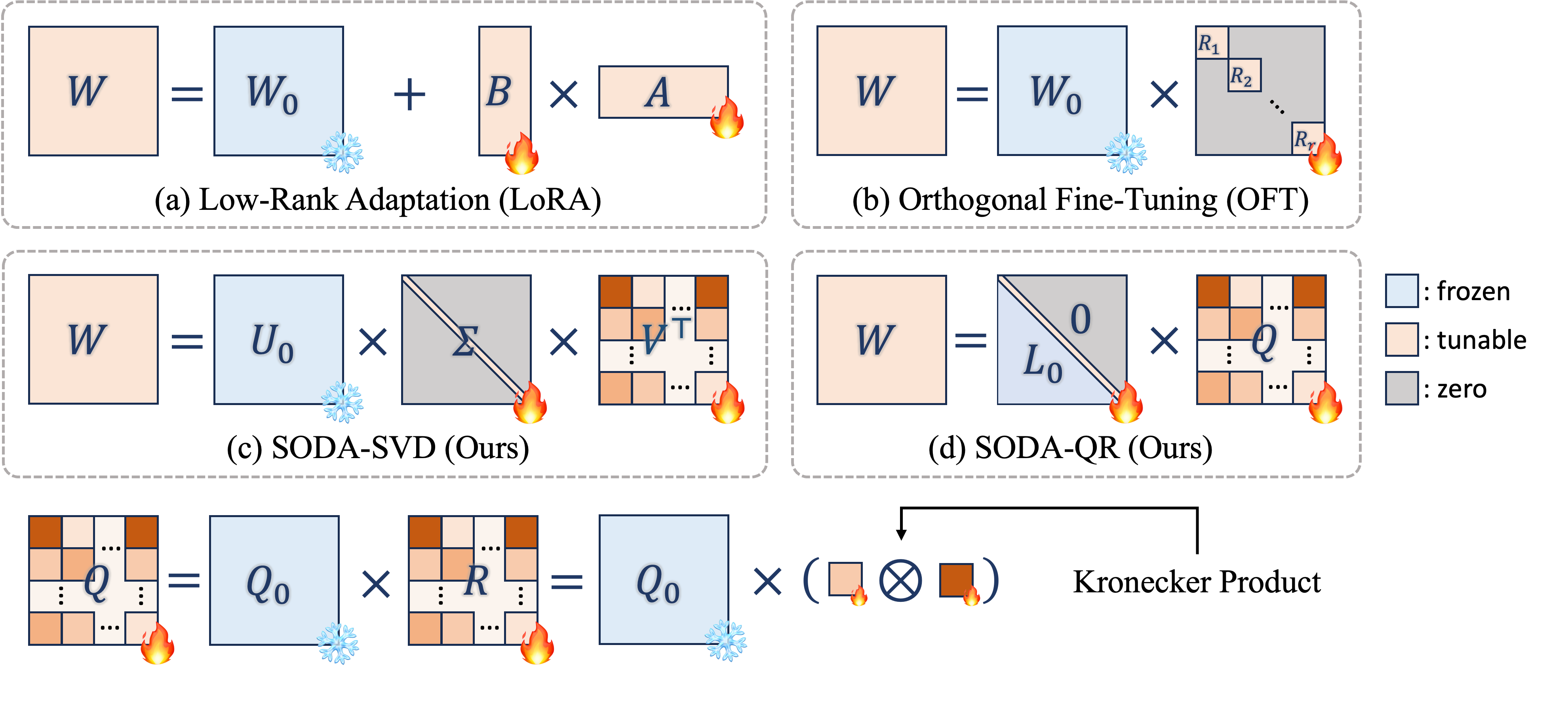
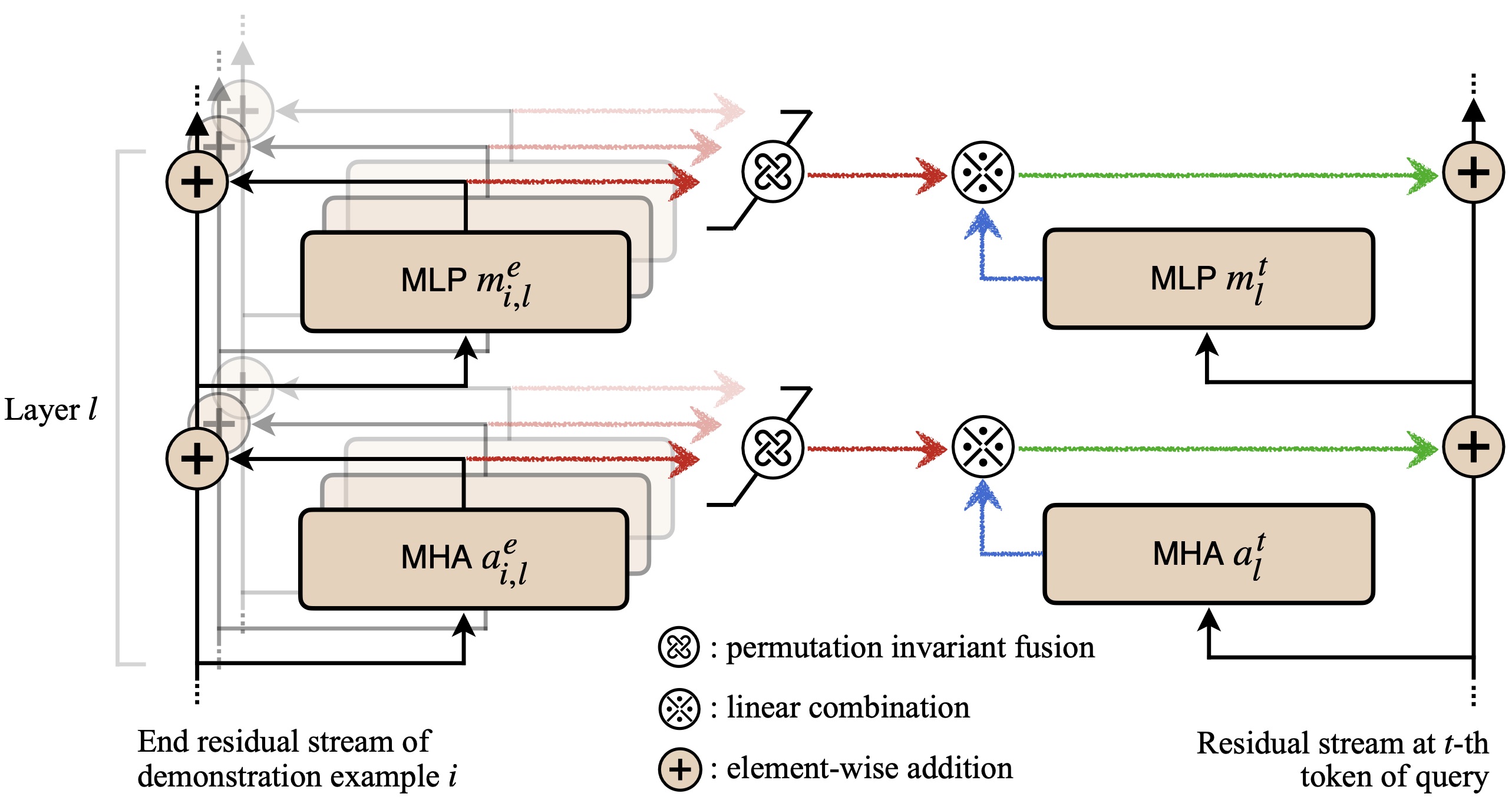
Unveiling the Secret Recipe: A Guide For Supervised Fine-Tuning Small LLMs
Aldo Pareja, Nikhil Shivakumar Nayak, Hao Wang, Krishnateja Killamsetty, Shivchander Sudalairaj, Wenlong Zhao, Seungwook Han, Abhishek Bhandwaldar, Guangxuan Xu, Kai Xu, Ligong Han, Luke Inglis, Akash Srivastava.
Accepted to International Conference on Learning Representations (ICLR), 2025
[arXiv]
[InstructLab]
[bibtex]
|
|
|
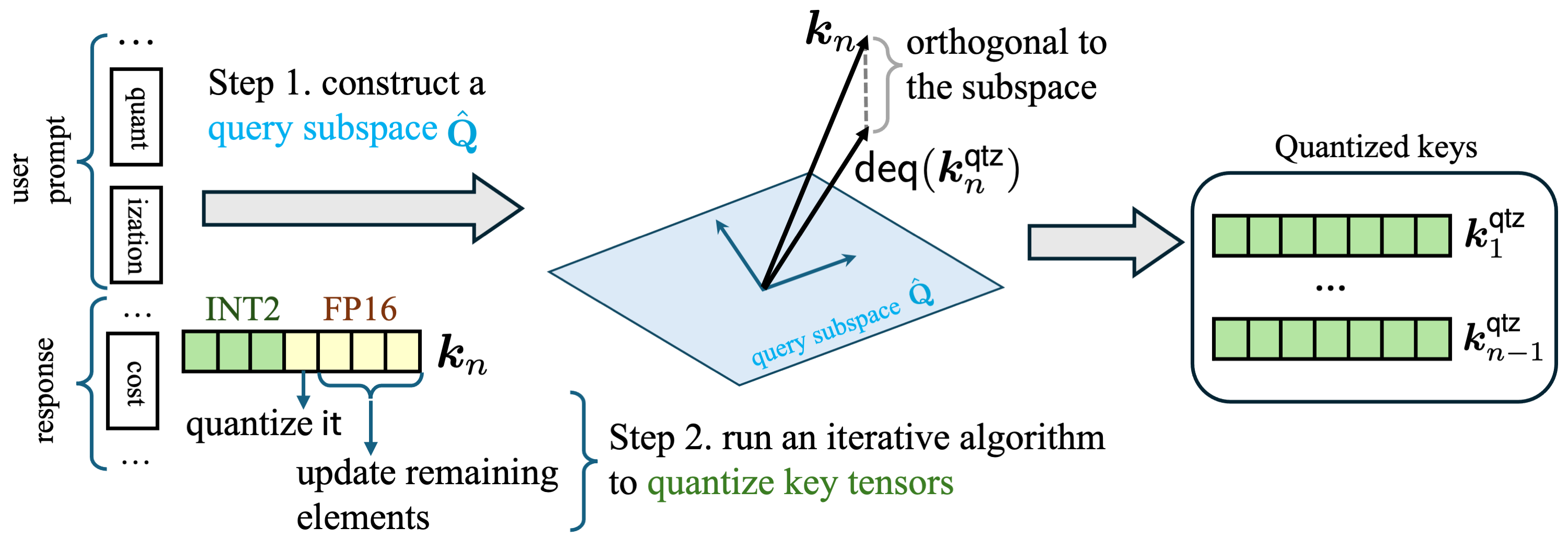
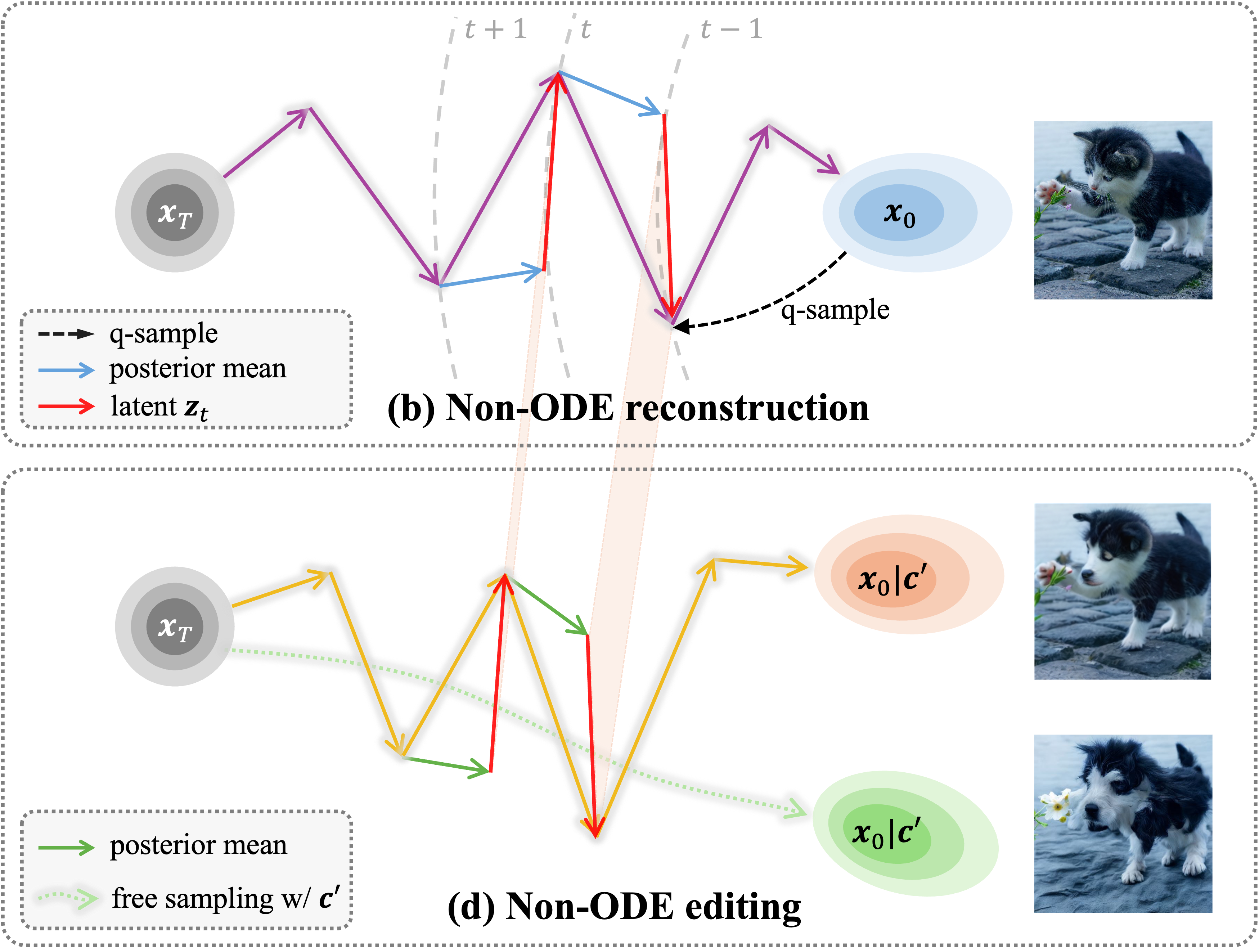
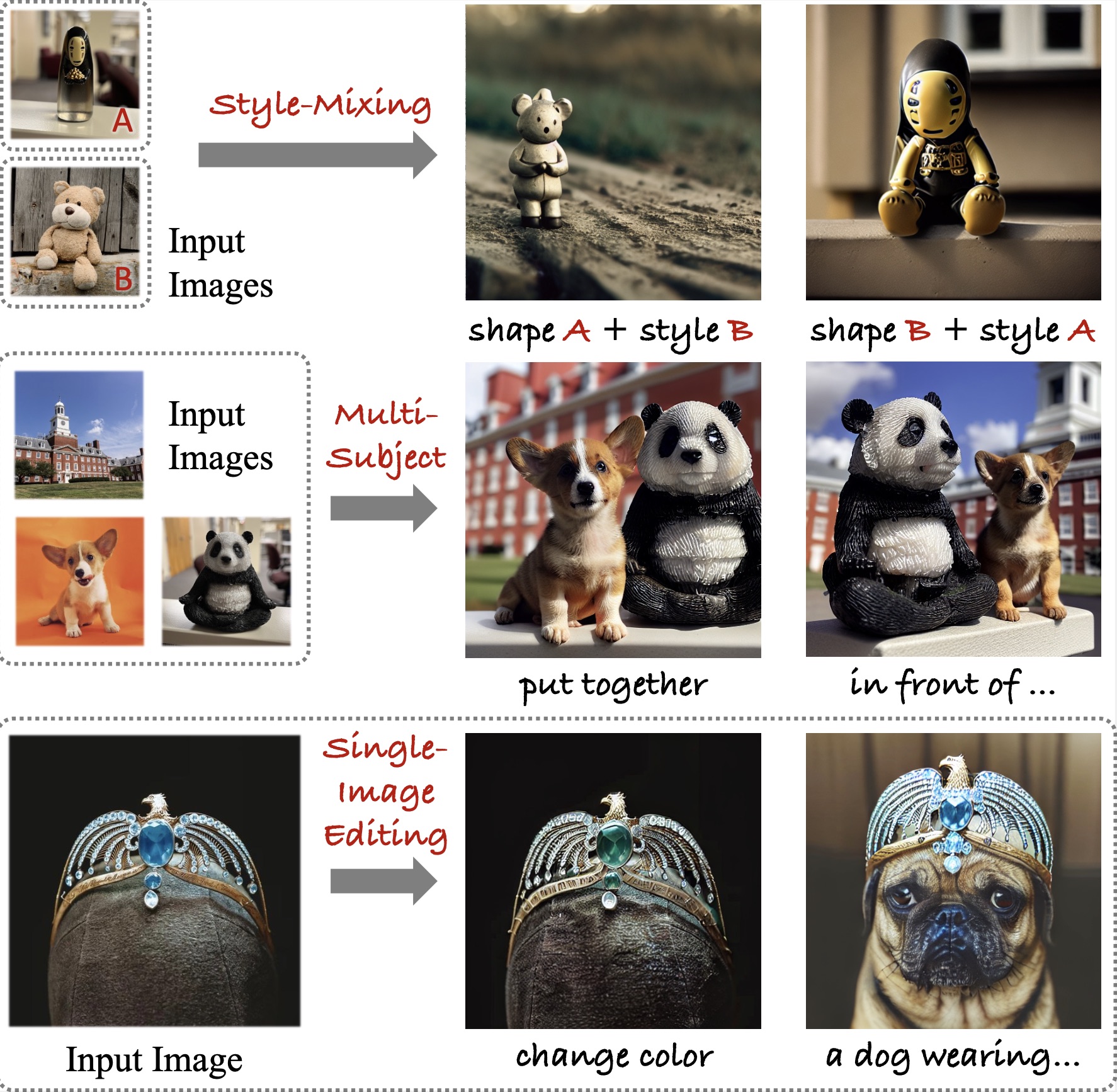
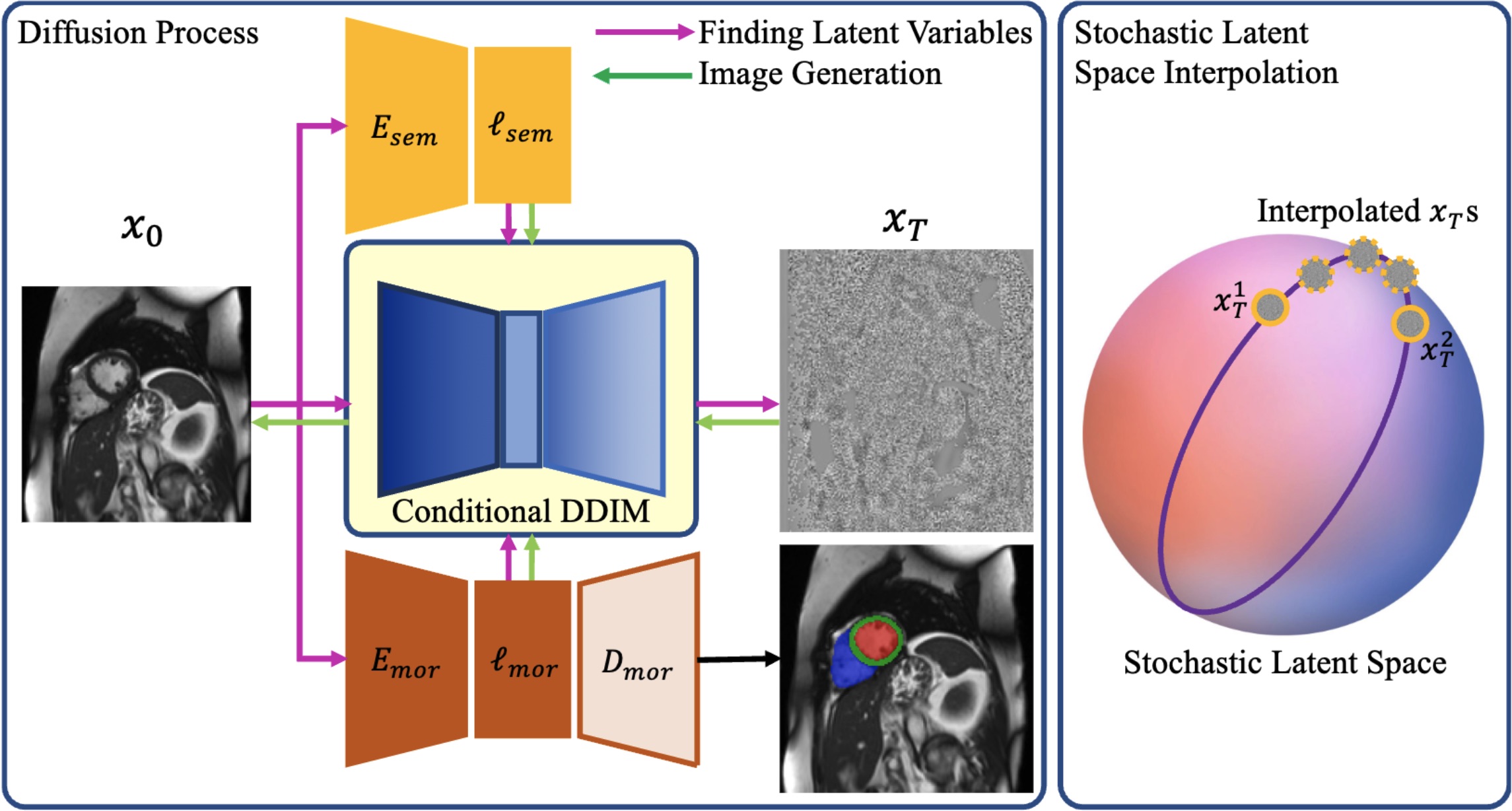
🎲 DICE: Discrete Inversion Enabling Controllable Editing for Multinomial Diffusion and Masked Generative Models
Xiaoxiao He, Ligong Han†, Quan Dao, Song Wen, Minhao Bai, Di Liu, Han Zhang, Martin Renqiang Min, Juefei Xu, Chaowei Tan, Bo Liu, Kang Li, Hongdong Li, Junzhou Huang, Faez Ahmed, Akash Srivastava, Dimitris Metaxas.
Accepted to Winter Conference on Applications of Computer Vision (WACV), 2026
[arXiv]
[Project Page]
[bibtex]
|
|
|
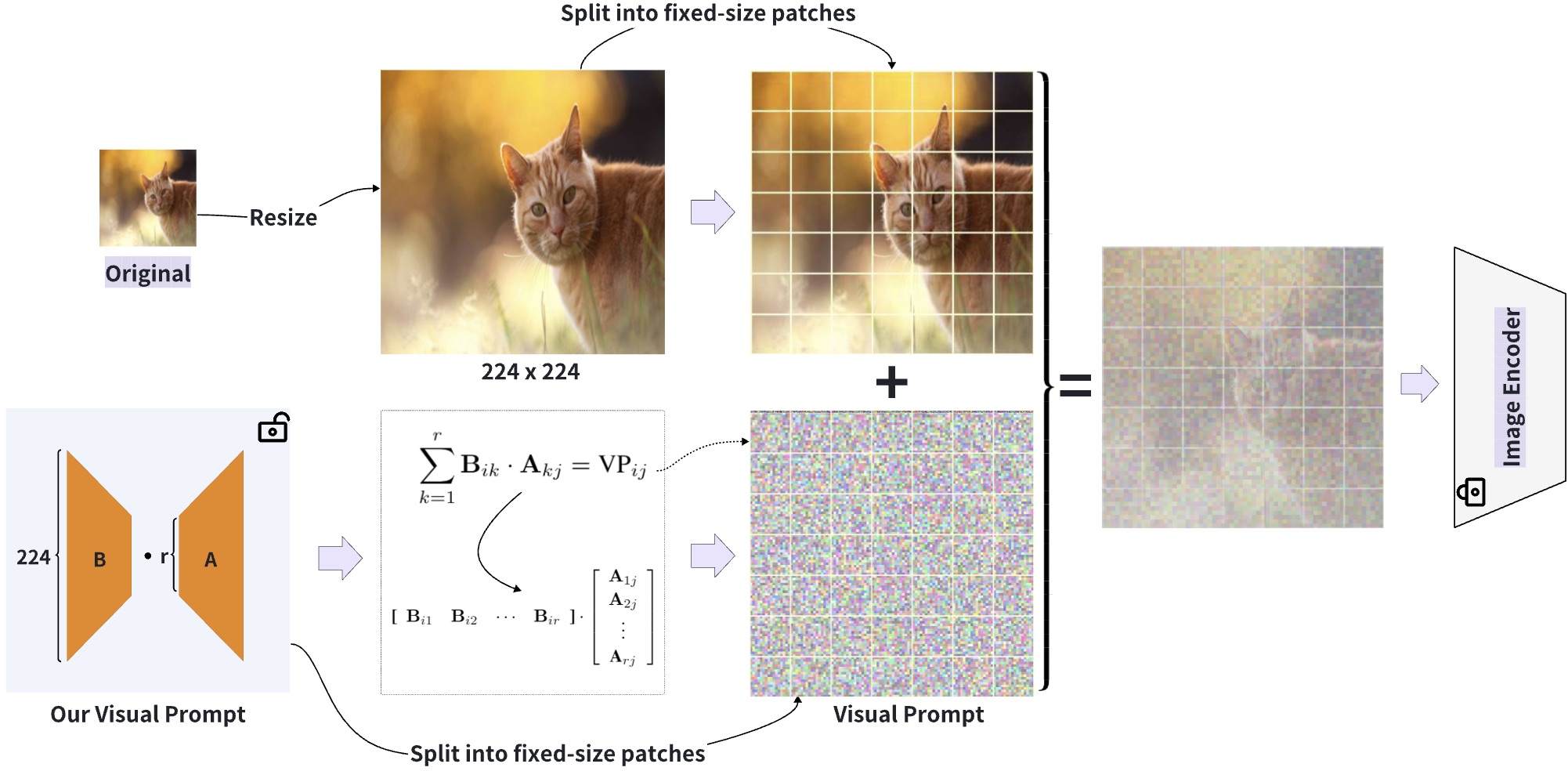
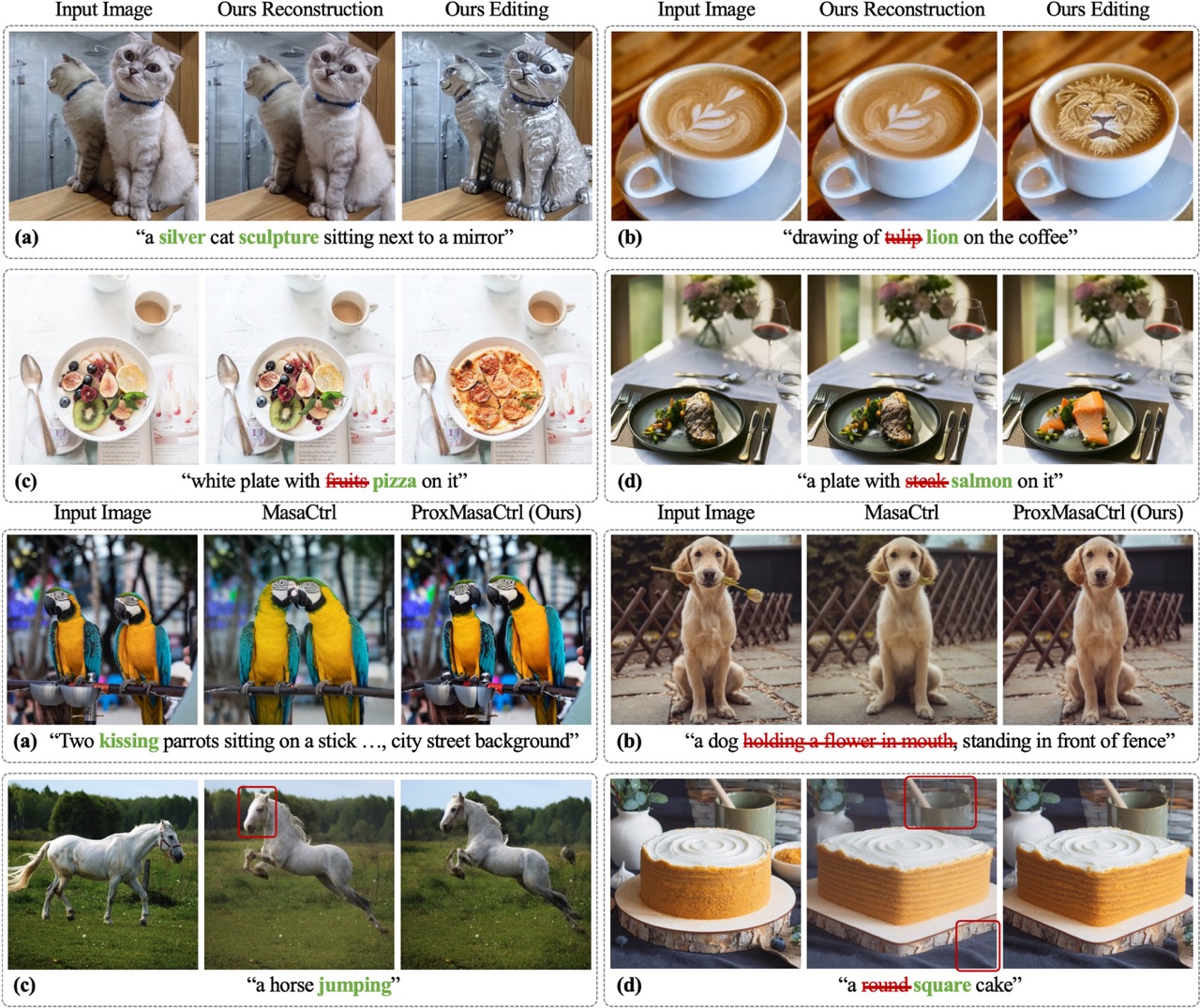
ProxEdit: Improving Tuning-Free Real Image Editing with Proximal Guidance
Ligong Han†, Song Wen, Qi Chen, Zhixing Zhang, Kunpeng Song, Mengwei Ren, Ruijiang Gao, Yuxiao Chen, Di Liu, Qilong Zhangli, Anastasis Stathopoulos, Jindong Jiang, Zhaoyang Xia, Akash Srivastava, Dimitris Metaxas.
Accepted at Winter Conference on Applications of Computer Vision (WACV), 2024
[arXiv]
[poster]
[Github]
[bibtex]
|
|
|
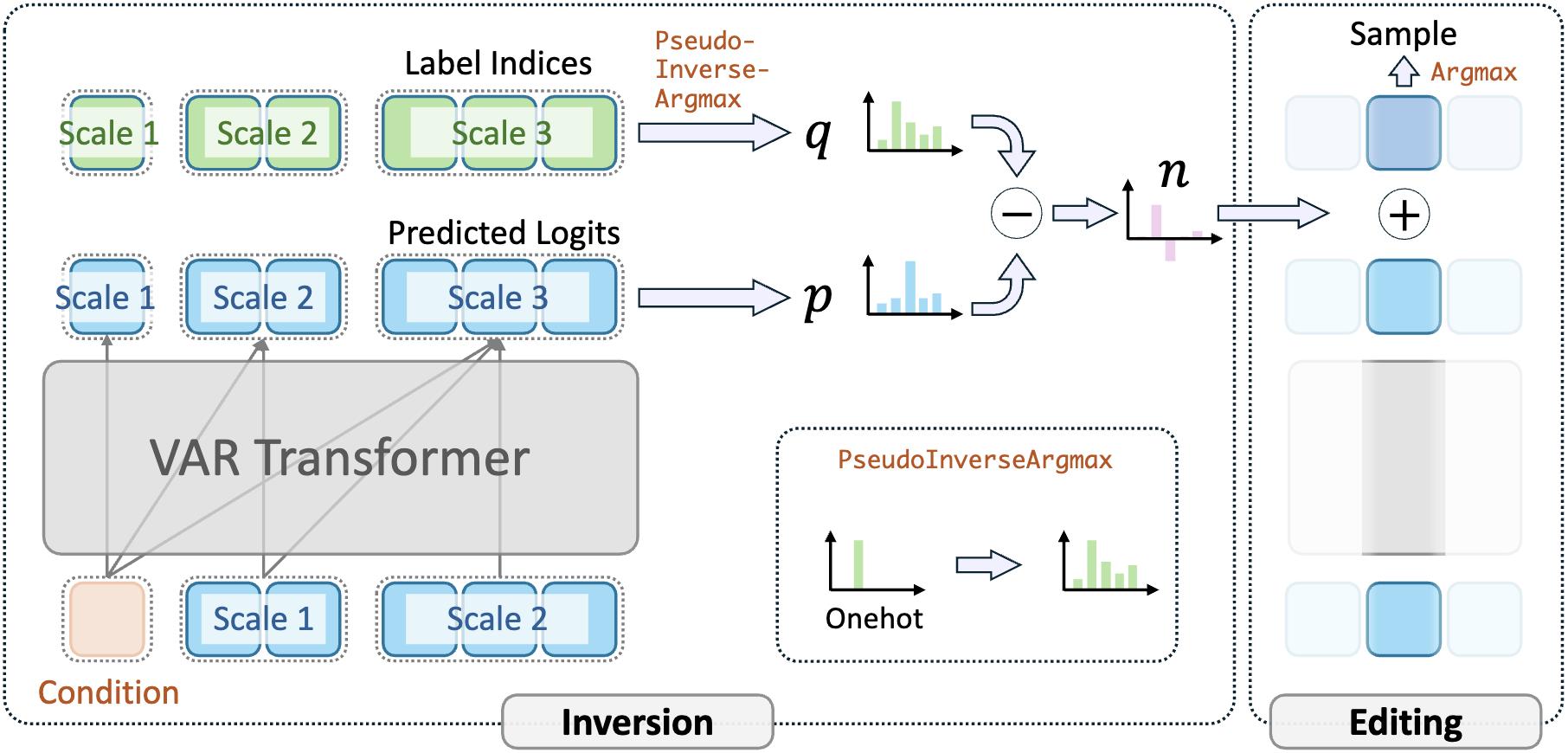
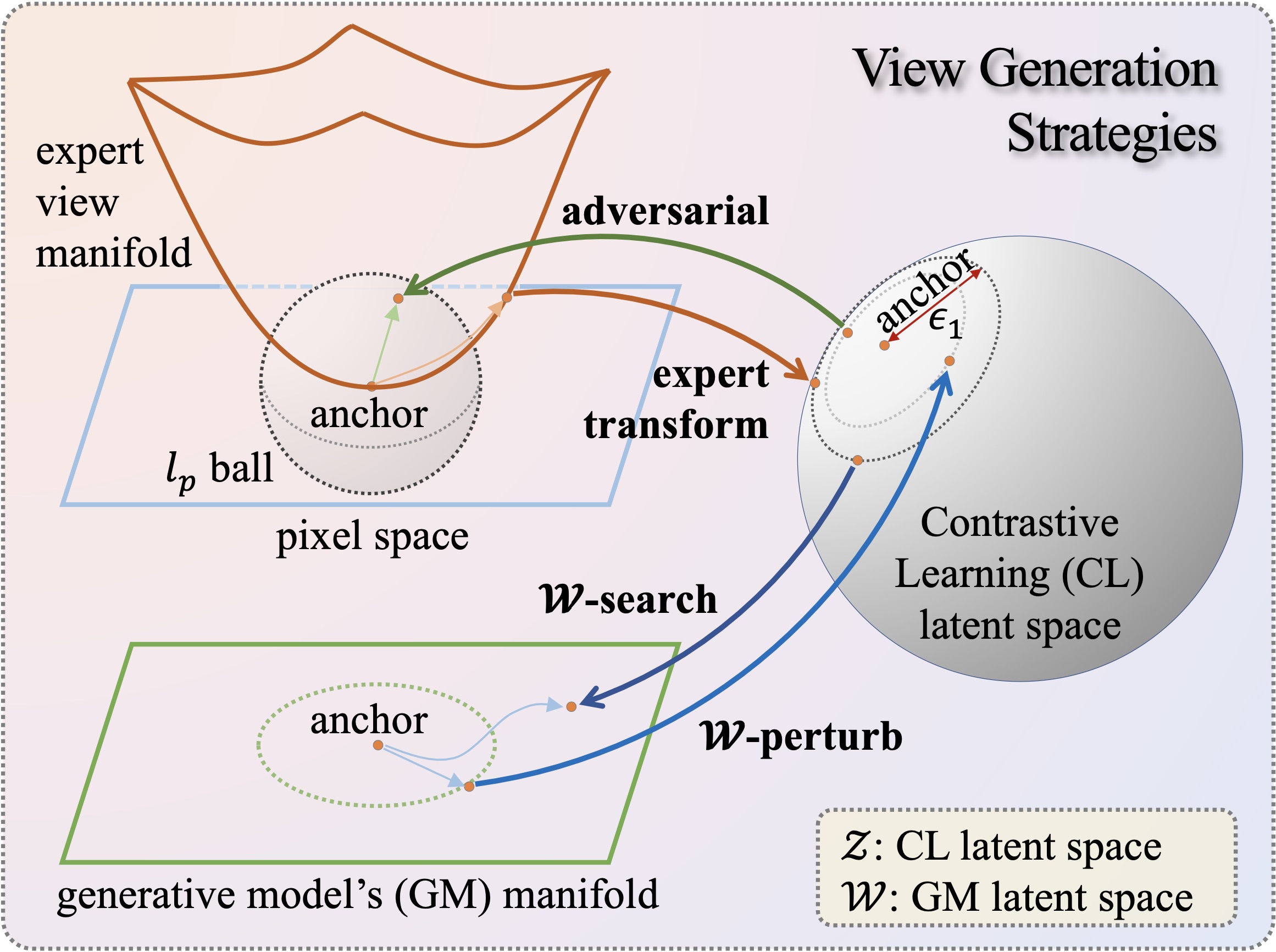
Constructive Assimilation: Boosting Contrastive Learning Performance through View Generation Strategies
Ligong Han†, Seungwook Han, Shivchander Sudalairaj, Charlotte Loh, Rumen Dangovski, Fei Deng, Pulkit Agrawal, Dimitris Metaxas, Leonid Karlinsky, Tsui-Wei Weng, Akash Srivastava.
Accepted to Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), 2023
[arXiv]
[poster]
[Github]
[bibtex]
|
|
|
[2015]
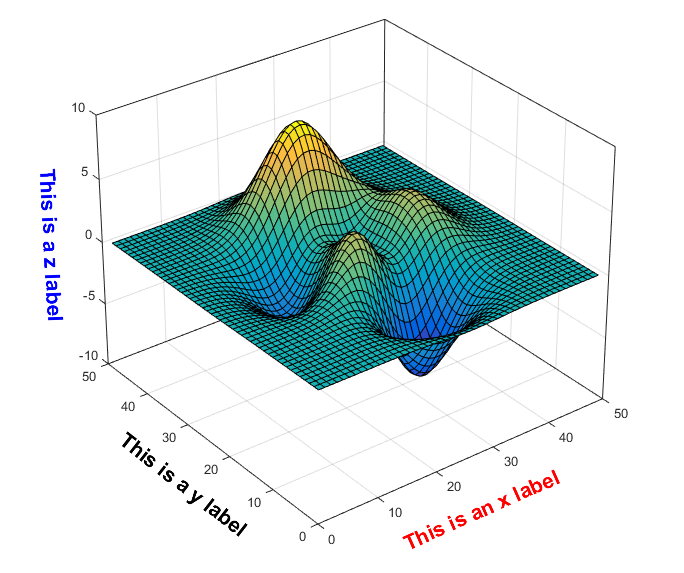
MATLAB Code for Axis Label Alignment in 3D Plots
[File Exchange]
[Github]
Align axis labels nicely in parallel with axes in MATLAB (3-D) plots. This file was selected as MATLAB Central Pick of the Week.
|
|